大语言模型「懂不懂你」取决于它能获取到多少你有价值的数据。所以能无感,或低门槛的让你把有价值的数据交给它至关重要。
从这个角度看,微软、谷歌是最有潜力打造出真正基于大语言模型的生产力工具。前者有 office 这个全世界最受欢迎的办公套件,后者也有一套用户基数很大的办公套件,以及持续收集用户数据的搜索引擎和浏览器。
国内在这方面最有潜力的还是字节跳动。飞书虽然市占率不高,但是飞书已经基于豆包推出了知识问答,可以全量获取用户飞书内的所有聊天记录、文档、知识库等数据。
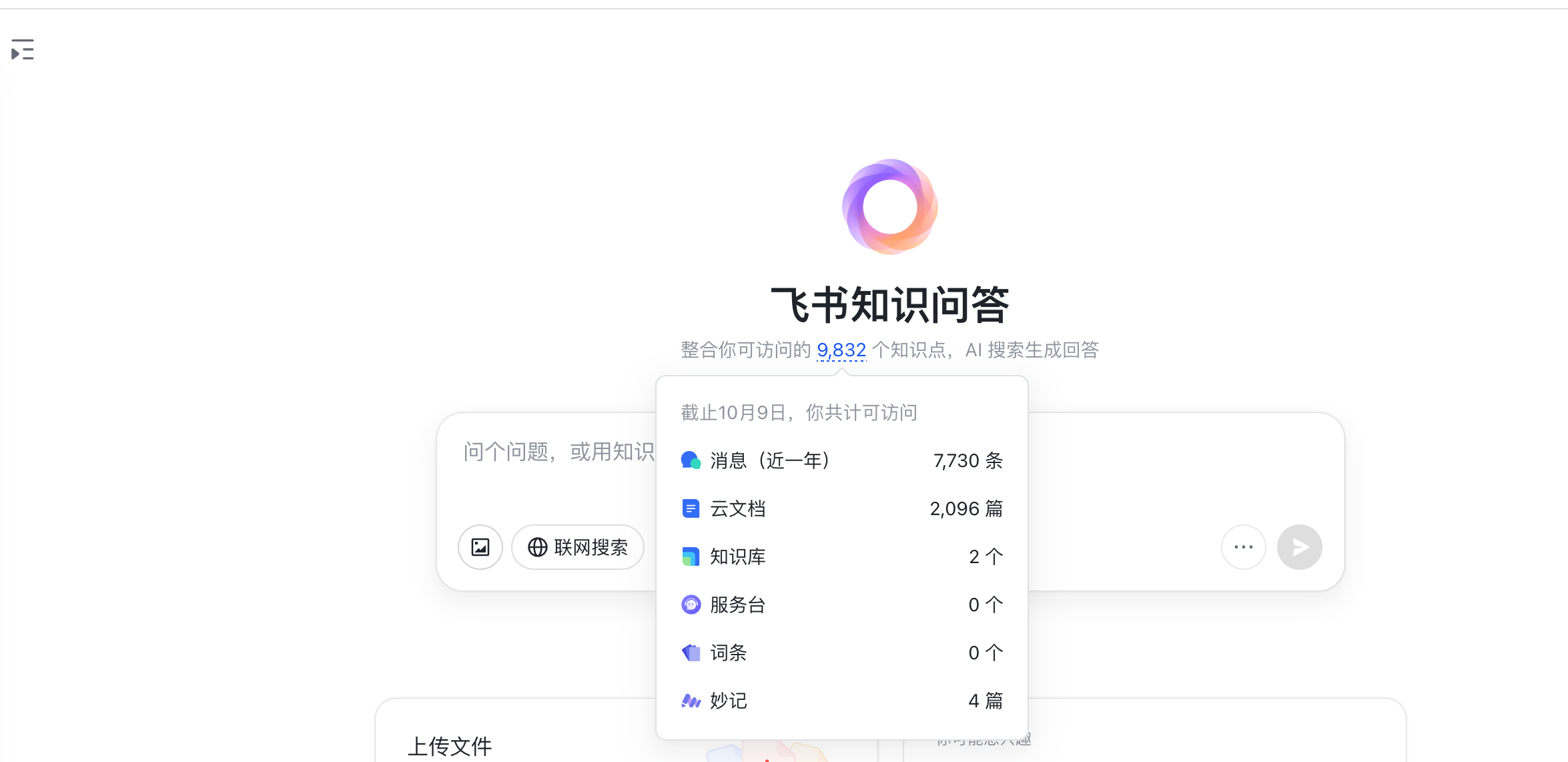
字节在这方面唯一的短板是不像 OpenAI 能做开放平台打通第三方服务(让腾讯和阿里把自己的数据开放给字节?这不可能),也不像 Google 本身就是一个小商业生态系统,用户能在里面满足一部分需求(现在已经打通了 Google 酒旅和 YouTube)。
腾讯也掌握了微信这个数据富矿,可惜微信里大部分都是聊天这种垃圾数据。企业微信和腾讯文档本身产品力不行,远远不如飞书好用。我甚至怀疑他们底层的数据架构也不如飞书开放灵活,想要打通、整合,可能还需要付出一点代价。
阿里有钉钉,但是我不清楚钉钉文档有多少人在用。在我的印象里,钉钉文档应该远不如飞书那么好用。而且钉钉文档的底层数据架构应该也不如飞书。现在钉钉文档 AI 也不能全量获取用户数据,还需要用户手动导入知识库,支持的格式也有限。